聊聊分布式系统的挑战
Everything fails, all the time -- Werner Vogels (Amazon's CTO)
构建分布式系统的可靠性,就需要面对各种系统出错的可能。本文主要目的是列举出分布式系统下所面对的各种挑战
注:这里的分布式系统是指 shard nothing 模式。无共享 并不是构建分布式系统的唯一方式,但它已经成为构建互联网服务的主要方式,其原因如下:相对便宜,因为它不需要特殊的硬件,可以利用商品化的云计算服务,通过跨多个地理分布的数据中心进行冗余可以实现高可靠性
不可靠的网络
- 请求可能已经丢失(可能有人拔掉了网线
- 请求可能正在排队,无法马上发送(也许网络或接收方过载)
- 远程node可能down
- 远程节点可能暂时停止了响应(可能会遇到长时间的垃圾回收暂停如java GC),稍后会响应
- 远程节点可能已经处理了请求,但是网络上的响应已经丢失(可能是网络交换机配置错误)
- 远程节点可能已经处理了请求,但是响应已经被延迟,并且稍后将被传递(可能是网络或者你自己的机器过载)
总之,如果发送请求并没有得到响应,则无法区分(a)请求是否丢失,(b)远程节点是否关闭,或(c)响应是否丢失
更技术化的总结:
- 消息发送是不可靠的
- 消息确认是困难的
- 消息是可能重复发送的
处理这个问题的机制通常采用timeout
检测故障
心跳+超时
详细见(https://guming.lol/posts/failure-detection)
超时与无限期的延时
超时时间的设置没有标准?
过长的时间,需要更长的等待才发现故障节点。
过短的时间,虽然可以快速感知故障节点,但可能会出现误判。如果是带有leader election的系统,新旧leader很可能对同一个数据执行多次操作等等
理想的超时设置:
- 网络数据包最大处理延时d
- 非故障节点r时间内完成请求
- 理想超时时间:2d+r
Network congestion and queueing
网络上数据包延迟的可变性通常是由于排队
-
如果多个不同的节点同时尝试将数据包发送到同一目的地,则网络交换机必须将它们排队并将它们逐个送入目标网络链路.在繁忙的网络链路上,数据包可能需要等待一段时间才能获得发送机会(这称为网络拥塞)。如果数据量大,交换机队列填满,数据包将被丢弃,因此需要重新发送数据包
-
当数据包到达目标机器时,如果所有 CPU 内核当前都处于繁忙状态,则来自网络的传入请求将被操作系统排队,直到应用程序准备好处理它为止。根据机器上的负载,这可能需要一段不确定的时间
-
在虚拟化环境中,正在运行的操作系统经常暂停几十毫秒,因为另一个虚拟机正在使用 CPU 内核。在这段时间内,虚拟机不能从网络中接收任何数据,所以传入的数据被虚拟机排队(缓冲),进一步增加了网络延迟的不确定性
-
TCP 执行 流量控制。其中节点会限制自己的发送速率以避免网络链路或接收节点过载。这意味着甚至在数据进入网络之前,在发送者处就需要进行额外的排队
如果 TCP 在某个超时时间内没有被确认(这是根据观察的往返时间计算的),则认为数据包丢失,丢失的数据包将自动重新发送。尽管应用程序没有看到数据包丢失和重新传输,但它看到了延迟
同步与异步网络
如果我们可以依靠网络来传递一些 最大延迟固定 的数据包,而不是丢弃数据包,那么分布式系统就会简单得多。为什么我们不能在硬件层面上解决这个问题呢?
比较数据中心网络与非常可靠的传统固定电话网络(非蜂窝,非 VoIP)
当你通过电话网络拨打电话时,它会建立一个电路:在两个呼叫者之间的整个路线上为呼叫分配一个固定的,有保证的带宽量。这个电路会保持至通话结束
这种网络是同步的:即使数据经过多个路由器,也不会受到排队的影响,因为呼叫的 16 位空间已经在网络的下一跳中保留了下来。而且由于没有排队,网络的最大端到端延迟是固定的。我们称之为 有限延迟
如果数据中心网络和互联网是电路交换网络,那么在建立电路时就可以建立一个受保证的最大往返时间。但是以太网和 IP 是 分组交换协议,不得不忍受排队和因此导致的网络无限延迟
为什么数据中心网络和互联网使用分组交换?因为互联网传输的数据是不可预测的,你不知道一个请求需要返回的数据有多少,也无法预估请求的数据。
一个电路适用于音频或视频通话,在通话期间需要每秒传送相当数量的比特,这个数据是可以预估的。
TCP 动态调整数据传输速率以适应可用的网络容量
不可靠的时钟
理解时间在系统里的表现 应用程序以各种方式依赖于时钟来回答以下问题:
- 这个请求是否超时了?
- 这项服务的第 99 百分位响应时间是多少?
- 用户在我们的网站上花了多长时间?
- 在过去五分钟内,该服务平均每秒处理多少个查询?
- 在什么时间发送提醒邮件?
- 这个缓存条目何时到期?
- 日志文件中此错误消息的时间戳是什么?
- 这篇文章在何时发布?
例 1-4 测量了 持续时间(durations,例如,请求发送与响应接收之间的时间间隔),而 例 5-8 描述了 时间点(point in time,在特定日期和和特定时间发生的事件)
单调钟与日历时钟
日历时钟
-
我们可以理解的自然时间
- Java 中的 System.currentTimeMillis() 返回自 epoch(UTC 时间 1970 年 1 月 1 日午夜)以来的秒数(或毫秒),根据公历(Gregorian)日历,不包括闰秒
-
日历时钟通常与 NTP 同步
单调钟
- 单调钟适用于测量持续时间(时间间隔),例如超时或服务的响应时间:Java 中的 System.nanoTime() 都是单调时钟
在分布式系统中,使用单调钟测量 经过时间(elapsed time,比如超时)通常很好,因为它不假定不同节点的时钟之间存在任何同步,并且对测量的轻微不准确性不敏感
时钟同步与准确性
- 计算机中的石英钟不够精确:它会 漂移(drifts,即运行速度快于或慢于预期)。时钟漂移取决于机器的温度。Google 假设其服务器时钟漂移为 200 ppm(百万分之一)。相当于每 30 秒与服务器重新同步一次的时钟漂移为 6 毫秒,或者每天重新同步的时钟漂移为 17 秒。即使一切工作正常,此漂移也会限制可以达到的最佳准确度
- 如果计算机的时钟与 NTP 服务器的时钟差别太大,可能会拒绝同步,或者本地时钟将被强制重置
- 如果某个节点被 NTP 服务器的防火墙意外阻塞,有可能会持续一段时间都没有人会注意到
- NTP同步受网络延时影响
- 在虚拟机中,硬件时钟被虚拟化,这对于需要精确计时的应用程序提出了额外的挑战【50】。当一个 CPU 核心在虚拟机之间共享时,每个虚拟机都会暂停几十毫秒,与此同时另一个虚拟机正在运行。从应用程序的角度来看,这种停顿表现为时钟突然向前跳跃
如果你足够在乎这件事并投入大量资源,就可以达到非常好的时钟精度。例如,针对金融机构的欧洲法规草案 MiFID II 要求所有高频率交易基金在 UTC 时间 100 微秒内同步时钟,以便调试 “闪崩” 等市场异常现象,并帮助检测市场操纵 —— 不明所以😭
依赖同步时钟
事件顺序性
依赖时钟,在多个节点上对事件进行排序。例如,如果两个客户端写入分布式数据库,谁先到达? 哪一个更近?
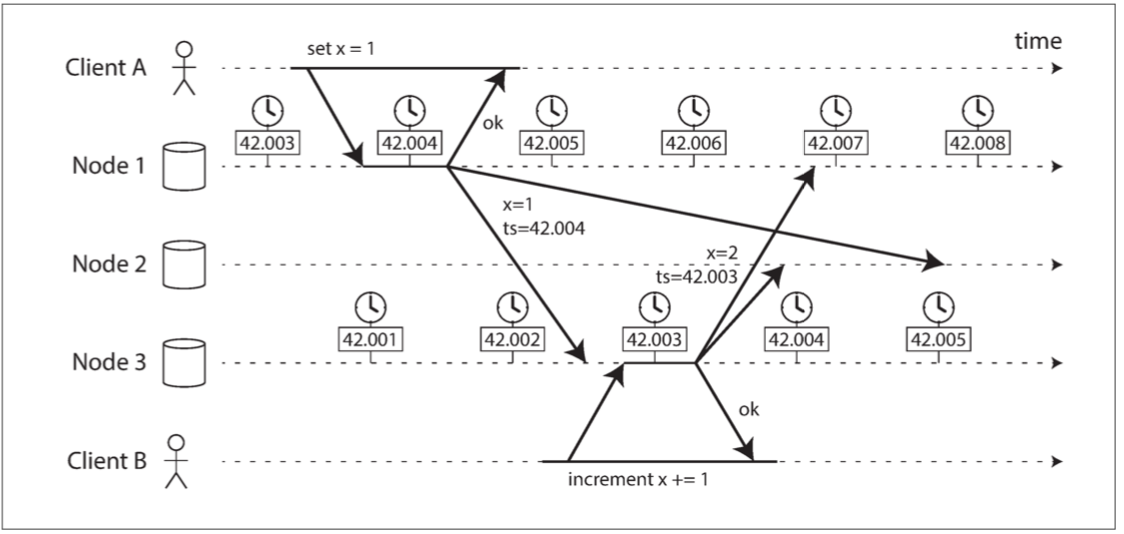
这种冲突解决策略被称为 最后写入胜利(LWW),它在多主复制和无主数据库中广泛使用
LWW也有如下问题:
- 两个节点很可能独立地生成具有相同时间戳的写入,特别是在时钟仅具有毫秒分辨率的情况下。为了解决这样的冲突,还需要一个额外的 决胜值(tiebreaker,可以简单地是一个大随机数)
- LWW 无法区分 高频顺序写入(在客户端 B 的增量操作 一定 发生在客户端 A 的写入之后)和 真正并发写入(写入者意识不到其他写入者)。需要额外的因果关系跟踪机制(例如版本向量),以防止违背因果关系 - 参考dynamoDB处理写入冲突
- 数据库写入可能会神秘地消失:具有滞后时钟的节点无法覆盖之前具有快速时钟的节点写入的值
逻辑时钟(logic clock)是基于递增计数器而不是石英晶体,对于排序事件来说是更安全的选择
全局快照的同步时钟
快照隔离(联想MVCC - MySQL)最常见的实现需要单调递增的事务 ID(GTID)。如果写入比快照晚(即,写入具有比快照更大的事务 ID),则该写入对于快照事务是不可见的。在单节点数据库上,一个简单的计数器就足以生成事务 ID
但是当数据库分布在许多机器上,也许可能在多个数据中心中时,由于需要协调,(跨所有region)全局单调递增的事务 ID 会很难生成。事务 ID 必须反映因果关系:如果事务 B 读取由事务 A 写入的值,则 B 必须具有比 A 更大的事务 ID,否则快照就无法保持一致。在有大量的小规模、高频率的事务情景下,在分布式系统中创建事务 ID 成为一个瓶颈
我们可以使用同步时钟的时间戳作为事务 ID吗?如果我们能够获得足够好的同步性,那么这种方法将具有很合适的属性:更晚的事务会有更大的时间戳。当然,问题在于时钟精度的不确定性
Spanner 以这种方式实现跨数据中心的快照隔离。它使用 TrueTime API 报告的时钟置信区间,并基于以下观察结果:如果你有两个置信区间,每个置信区间包含最早和最晚可能的时间戳($A = [A{earliest}, A{latest}]$,$B=[B{earliest}, B{latest}]$),这两个区间不重叠(即:$A{earliest} <A{latest} <B{earliest} <B{latest}$)的话,那么 B 肯定发生在 A 之后 —— 这是毫无疑问的。只有当区间重叠时,我们才不确定 A 和 B 发生的顺序
为了确保事务时间戳反映因果关系,在提交读写事务之前,Spanner 在提交读写事务时,会故意等待置信区间长度的时间。通过这样,它可以确保任何可能读取数据的事务处于足够晚的时间,因此它们的置信区间不会重叠。为了保持尽可能短的等待时间,Spanner 需要保持尽可能小的时钟不确定性,为此,Google 在每个数据中心都部署了一个 GPS 接收器或原子钟,这允许时钟同步到大约 7 毫秒以内--还是靠硬件😄
进程暂停
这个问题容易理解,但经常被忽视
让我们考虑在分布式系统中使用时钟的另一个例子。假设你有一个数据库,每个分区只有一个领导者。只有主节点被允许接受写入。其他节点如何知道它仍然是领导者(它并没有被别人宣告为死亡),并且可以安全地写入?
一种选择是领导者从其他节点获得一个租约(lease),类似一个带超时的锁。
任一时刻只有一个节点可以持有租约 —— 因此,当一个节点获得一个租约时,它知道它在某段时间内自己是领导者,直到租约到期。为了保持领导地位,节点必须周期性地在租约过期前续期
如果节点发生故障,就会停止续期,所以当租约过期时,另一个节点可以接管。
问题发生在主节点出现了意外的停顿呢?如jvm GC/线程被挂起/访问磁盘被blocked等。 所有情况事件都可以随时 抢占正在运行的leader线程,并在稍后的时间恢复运行,而leader线程甚至不会注意到这一点
leader还以为自己没有过期,而其他节点已经抢到了lease。导致两个主leader写入,破坏数据
一个解决办法是fencing Token:
- 单调递增的fencing token
- 写入时携带token
- server端拒绝旧的令牌写入
fencing Token算法的正确性:
-
唯一性
-
单调递增
-
可用性
- 请求token的节点如果不发生崩溃一定会收到响应
在单机上写多线程的代码,可以通过Mutex/Semaphore/Atomic计数器/Lock-free数据结构/Bloking Queue保证线程安全
但分布式系统不行,节点间无法共享内存
分布式系统中的节点,必须假定其执行可能在任意时刻暂停相当长的时间。在暂停期间,世界的其它部分在继续运转,甚至可能因为该节点没有响应,而宣告暂停节点的死亡——😄
调整垃圾回收的影响
预测GC到来的时机或者在GC发起时,提醒服务消费者,已接受的请求会继续处理,但不再接受新的请求。这个技巧向服务消费者隐藏了 GC 暂停,降低了吞吐量,但减少了延时。一些对延迟敏感的金融交易系统使用这种方法。
这个想法的一个变种是只用垃圾收集器来处理短命对象。rolling update一样,定时滚动重启服务——😄听着像土法炼钢
真相由多数人决定
分布式系统不能完全依赖单个节点,因为节点可能随时失效,可能会使系统卡死,无法恢复(👆进程暂停问题)
许多分布式算法都依赖于法定人数,即在节点之间进行投票:决策需要来自多个节点的最小投票数,以减少对于某个特定节点的依赖
最常见的法定人数是超过半数以上,Quorum机制
总结
部分失效(partial failure)是分布式系统的决定性特征
为了容忍错误,第一步是检测。大多数系统没有检测节点是否发生故障的准确机制,所以大多数分布式算法依靠timeout来确定远程节点是否仍然可用。但是,超时无法区分网络失效和节点失效,并且可变的网络延迟有时会导致节点被错误地怀疑发生故障
一旦检测到故障,使系统容忍它也并不容易:没有全局变量,没有共享内存,没有约定的尝试或跨节点间的共享状态。节点甚至不能就现在是什么时间达成一致,就不用说其他的了
信息从一个节点流向另一个节点的唯一方法是通过不可靠的网络发送信息
重大决策不能由一个节点安全地完成,因此我们需要一个能从其他节点获得帮助的协议,并争取达到法定人数以达成一致
参考
DDIA