聊聊 Failure Detector
定义
在分布式计算系统中,故障检测器是一个计算机应用程序或一个子系统,负责检测节点的故障或崩溃。故障检测器最早在1996年由Chandra和Toueg在他们的书籍《Unreliable Failure Detectors for Reliable Distributed Systems》中引入。故障检测器广泛用于分布式计算系统中,用于检测应用程序错误
算法
故障检测算法需要体现的几个属性:
-
Safety 安全性
- 如果一个进程被标记为故障,那么这个进程必须是死的😊--像废话
-
liveness 活性
- 如果其中一个进程发生故障,则故障检测器必须检测到
-
Completeness 完备性
- 所有正常的进程都可以察觉到故障的进程
-
Efficiency 效率
-
效率更像是调节器
- 一个更高效的算法,很可能更不准确
- 一个更准确的算法,很可能不高效
-
许多分布式系统都使用了 heartbeats 来实现错误检测,这种方式流行的原因是因为它简单并且具有较强的完整性
Deadline Failure Detector
- heartbeat / ping + timeout
许多的错误检测算法都是基于心跳跟超时的,比如 Akka,实现了一个 Deadline failure detector,它使用心跳并在固定时间区间内进程无法成功注册时会被报告为故障状态
/**
* will return `false` if there is no [[#heartbeat]] within the duration
* `heartbeatInterval + acceptableHeartbeatPause`
*/
private def isAvailable(timestamp: Long): Boolean =
if (active) (heartbeatTimestamp + deadlineMillis) > timestamp
else true // treat unmanaged connections, e.g. with zero heartbeats, as healthy connections
override def isMonitoring: Boolean = active
final override def heartbeat(): Unit = {
heartbeatTimestamp = clock()
active = true
}
其中:
- deadlineMillis = acceptableHeartbeatPause.toMillis + heartbeatInterval.toMillis
- acceptableHeartbeatPause 在节点失效之前接受的心跳暂停的最大持续时间
- heartbeatInterval 心跳间隔
- heartbeatTimestamp 上一个心跳的时间戳,初始值为 0,直到第一次心跳活跃后才会使用
缺点:
- 依赖heartbeats的频率(间隔时间和次数)和timeout 时间的选择
- 发起heartbeats的进程如果出现问题,将影响准确性
适用场景
-
client/server间的检测
- 实现简单
Outsourced Heartbeat - 一种基于heartbeat的改进方案
从邻接节点的视角来提高活跃检测的可靠性。这个方式不会要求进程对网络中的其他进程都有所感知,只需要其感知已经连接的子集
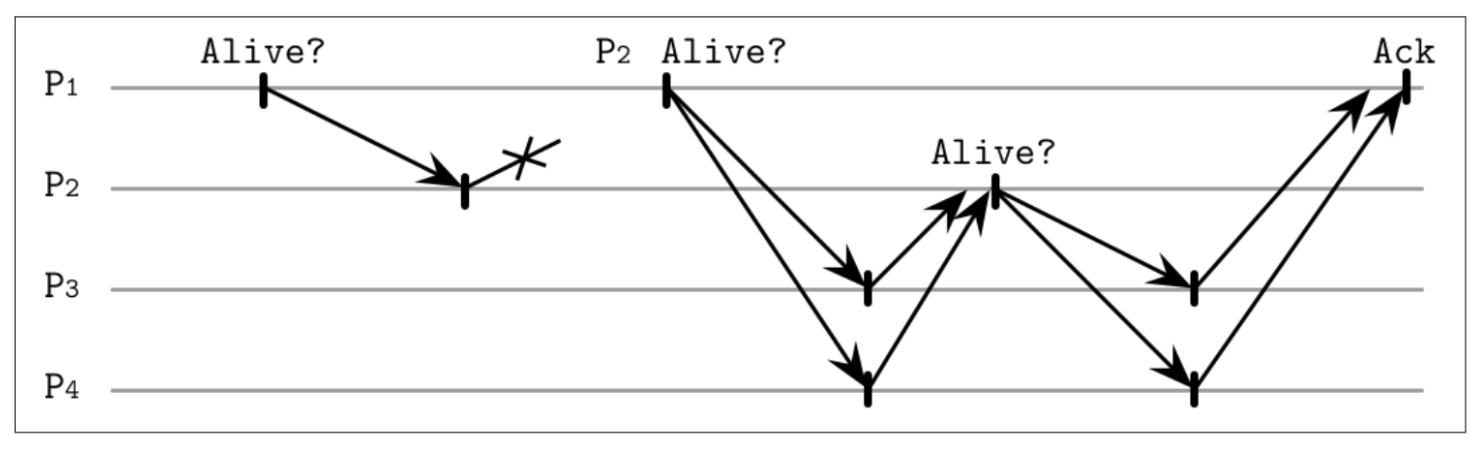
进程 P1 发送了 Ping 消息给进程 P2,P2 没有对该消息做出响应,因此 P1 随机的选择了多个随机成员 (P3 跟 P4)。这些随机的成员会尝试发送心跳信息给 P2,如果 P2 响应了消息,则他们会将响应的结果确认给 P1
外置心跳通过将故障检测分布到不同组的成员中来实现其可靠性。这种方式也不需要将消息广播到大量的节点。因为外置心跳的请求可以并行的触发,这种方式可以更快的收集到可疑节点的更多状态信息,以便我们能够做出更精准的决定。
Phi-Accural Failure Detector
针对dealine failure detector 准确性难题(详细见👆的缺点部分),业内给出了一个改进的算法
Phi-Accural (φ 增长) 故障检测器观察被监控进程崩溃的概率。通过管理一个滑动窗口来收集从其他进程发送过来的最新的心跳到达时间。这个信息会被用来估算下一个心跳的到达时间,通过对这个估算时间与真正的到达时间进行比较,来计算出一个 Suspicion level φ (怀疑级别 ) : 代表在当前网络下,故障检测器对故障的置信度
这个算法通过收集消息的到达时间并进行采样,创建了一个可以用来决定节点健康程度的视图。他用这些采样来计算 φ 的值:如果这个值达到了指定的阈值,节点就会被标识为失效。这个故障监测器通过调整被标识为可以节点的规模来动态适配网络条件的变化。
从整体架构的角度, Phi-Accural 故障监测器视为由以下三个子系统所组成的:
Monitoring
通过 Ping、心跳或请求-响应的采样来收集存活信息
Interpretation
负责决定进程是否该被标识为dead
Action
在进程被标识为可疑时负责启动指定的callback处理
实现(Akka):
override def isAvailable: Boolean = isAvailable(clock())
private def isAvailable(timestamp: Long): Boolean = phi(timestamp) < threshold
其中
-
threshold 判断是否可用的阈值
- 低阈值容易生成错误的怀疑,但在真实崩溃事件发生时能够快速检测
- 相反,高阈值生成的错误较少,但需要更多的时间来检测真实的崩溃
-
官网给出的最佳实践
- The default threshold is 8 and is appropriate for most situations. However in cloud environments, such as Amazon EC2, the value could be increased to 12 in order to account for network issues that sometimes occur on such platforms
-
timestamp 当前的系统时间milliseconds
-
phi函数如下:
- phi = -log10(1 - F(timeSinceLastHeartbeat)) 其中 F 是从历史心跳间隔时间估算得到的均值和标准差的正态分布的累积分布函数
private def phi(timestamp: Long): Double = {
val oldState = state.get
val oldTimestamp = oldState.timestamp
if (oldTimestamp.isEmpty) 0.0 // treat unmanaged connections, e.g. with zero heartbeats, as healthy connections
else {
val timeDiff = timestamp - oldTimestamp.get
val history = oldState.history
val mean = history.mean
val stdDeviation = ensureValidStdDeviation(history.stdDeviation)
phi(timeDiff, mean + acceptableHeartbeatPauseMillis, stdDeviation)
}
}
/**
* Calculation of phi, derived from the Cumulative distribution function for
* N(mean, stdDeviation) normal distribution, given by
* 1.0 / (1.0 + math.exp(-y * (1.5976 + 0.070566 * y * y)))
* where y = (x - mean) / standard_deviation
* This is an approximation defined in β Mathematics Handbook (Logistic approximation).
* Error is 0.00014 at +- 3.16
* The calculated value is equivalent to -log10(1 - CDF(y))
*/
private[akka] def phi(timeDiff: Long, mean: Double, stdDeviation: Double): Double = {
val y = (timeDiff - mean) / stdDeviation
val e = math.exp(-y * (1.5976 + 0.070566 * y * y))
if (timeDiff > mean)
-math.log10(e / (1.0 + e))
else
-math.log10(1.0 - 1.0 / (1.0 + e))
}
其中
-
state - 组合了 HeartbeatHistory 和 timestamp
- AtomicReference :: State(State(history = firstHeartbeat, timestamp = None))
-
HeartbeatHistory 进程的心跳统计信息
- 心跳internal list
- internalSum 心跳间隔和 = intervalSum + interval
- squaredIntervalSum 心跳间隔平方和= squaredIntervalSum + pow2(interval))
-
mean 计算 intervalSum.toDouble / intervals.size
-
stdDeviation 标准差计算 math.sqrt(variance)
-
variance 方差计算 (squaredIntervalSum.toDouble / intervals.size) - (mean * mean)
-
acceptableHeartbeatPauseMillis 来源于配置
- 不宜设置过短,容易出现假阳性:节点频繁出现 UNREACHABLE,然后是 REACHABLE
- 需要根据业务特点进行设置
缺点:
- 实现复杂
- acceptableHeartbeatPauseMillis 和 threshold 需要根据网络和业务需要进行配置
使用场景:
- server 集群 主从之间的故障检测
Gossip and Failure Detection
另一种能够避免依赖于单节点观点来做决定的方式是 Gossip-Style 故障检测服务,他使用了 gossip 算法来收集跟分发邻接进程的状态
每个成员都会管理一个其他成员的列表,心跳计数器以及时间戳,指示了心跳计数器最后一次增加计数的时间。每个成员会周期性的递增他的心跳计数器跟分发这个列表给一个随机的邻接节点,在收到这个消息后,邻接节点会将接收到的列表跟自身的列表进行合并,然后更新心跳计数器到其他的邻接节点。
节点也会周期性的检查列表中节点的状态跟心跳计数器,如果有节点在足够长的时间内都没有更新他的计数器,则会被当成发生了故障。
这个决定是可靠的,因为我们使用的是集群中多个节点聚合的观点。如果两个主机间的连接产生了故障,心跳依然可以通过其他的进程来进行传播。使用 Gossip 来传播系统的状态会增加系统中的消息数,但也能够让信息得到更高的可靠性
缺点:
- 节点较多的集群需要注意通信过程中的消息数量
- 实现复杂
参考
- Akka source code
- Database Internals