Redis源码 - Replication
如果要做一个服务的Replication,需要支持哪些功能
- 数据同步协议
- 全量复制 新的Replication 同步数据
- 实时复制 新的命令传播至slave,Replication可以实时(ASAP)同步
- 增量复制,Replication断线又上线,需要基于某个checkpoint 增量同步数据
- 支持多个Replication 同步数据
- 支持链式同步A->B->C,多副本模式下分担master压力
隐含的问题
- 传输机制
- ACK机制
- 容错机制
- 主从一致性
本文试着从这几方面下手,从Redis实现角度展开聊聊
数据同步协议
网络连接
slave启动,通过connectWithMaster 连接至master,普通的网络连接
master 通过epoll监听fd连接事件,anetTcpAccept处理连接
slave
(gdb) bt
#0 connectWithMaster () at replication.c:1879
#1 0x0000000000453aec in replicationCron () at replication.c:2553
#2 0x00000000004302f2 in serverCron (eventLoop=0x7ffff6c30050, id=0, clientData=0x0) at server.c:1318
#3 0x000000000042a4d6 in processTimeEvents (eventLoop=0x7ffff6c30050) at ae.c:331
#4 0x000000000042a87d in aeProcessEvents (eventLoop=0x7ffff6c30050, flags=11) at ae.c:469
#5 0x000000000042a996 in aeMain (eventLoop=0x7ffff6c30050) at ae.c:501
#6 0x0000000000437373 in main (argc=2, argv=0x7fffffffe428) at server.c:4197
master
(gdb) bt
#0 anetTcpAccept (err=0x7c92a0 <server+576> "accept: Resource temporarily unavailable", s=7, ip=0x7fffffffe1e0 "P\342\377\377\377\177", ip_len=46, port=0x7fffffffe214) at anet.c:551
#1 0x0000000000441a2a in acceptTcpHandler (el=0x7ffff6c30050, fd=7, privdata=0x0, mask=1) at networking.c:734
#2 0x000000000042a7b3 in aeProcessEvents (eventLoop=0x7ffff6c30050, flags=11) at ae.c:443
#3 0x000000000042a996 in aeMain (eventLoop=0x7ffff6c30050) at ae.c:501
#4 0x0000000000437373 in main (argc=2, argv=0x7fffffffe428) at server.c:4197
handshake
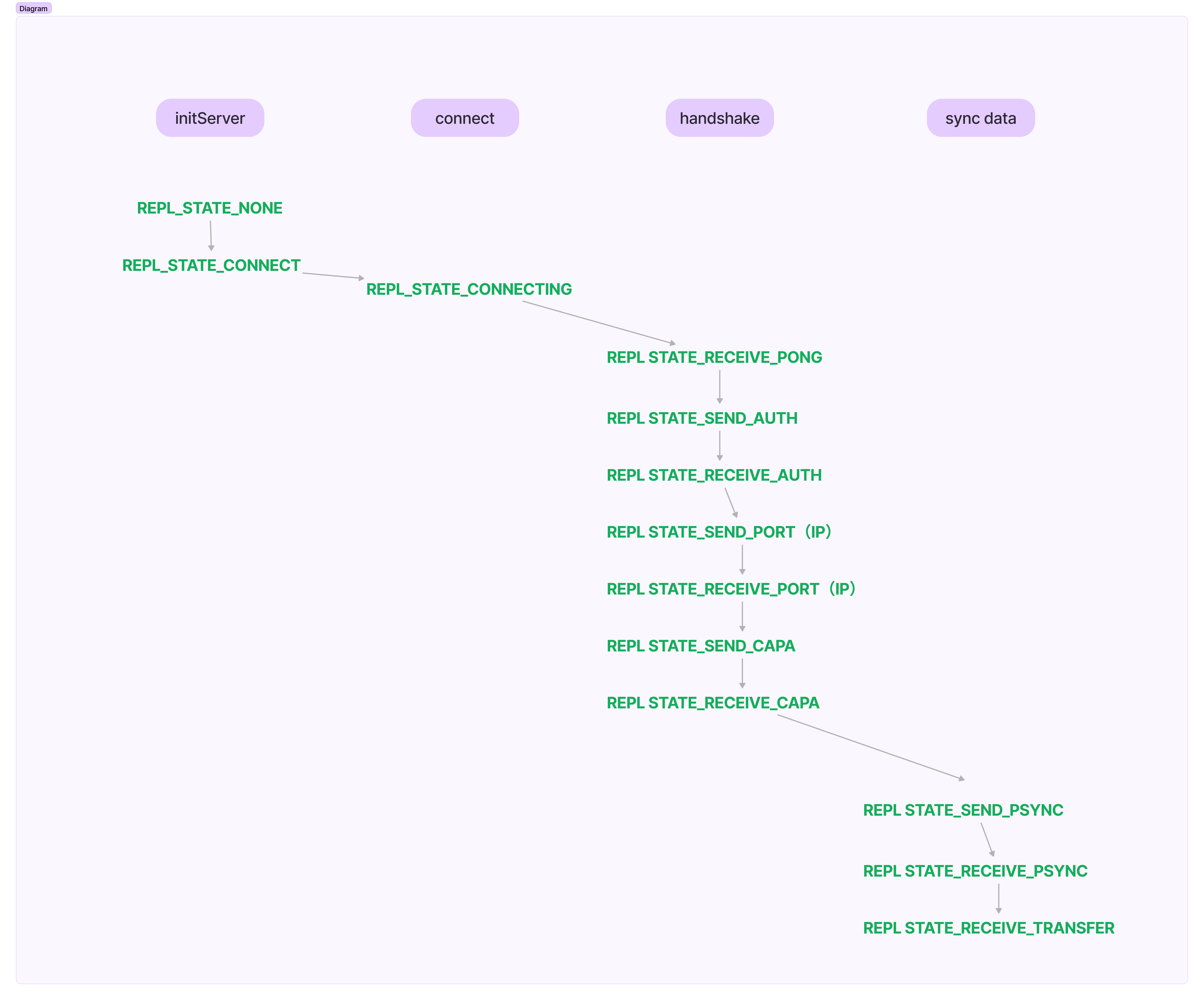
Redis维护了一个状态机 ,slave状态由REPL_STATE_CONNECTING->REPL_STATE_RECEIVE_PONG
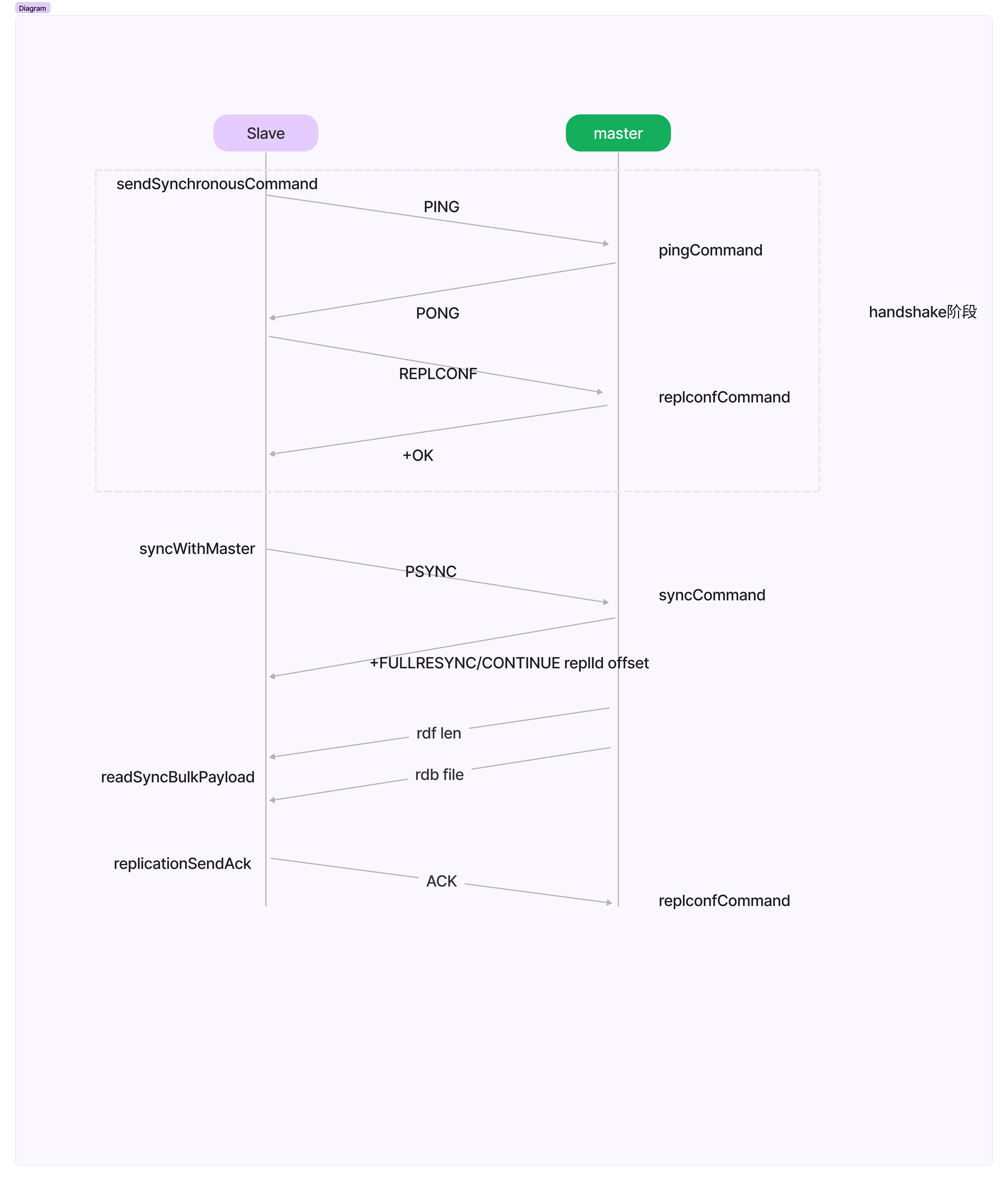
握手过程
- slave通过sendSynchronousCommand发送PING
- master执行pingCommand,回复PONG
- slave发送replconf,包括验证信息、端口号、IP、对 RDB 文件和无盘复制的支持情况
- master 回复+OK
slave
(gdb) bt
#0 sendSynchronousCommand (flags=2, fd=7) at replication.c:1334
#1 0x0000000000452005 in syncWithMaster (el=0x7ffff6c30050, fd=7, privdata=0x0, mask=2) at replication.c:1632
#2 0x000000000042a7fe in aeProcessEvents (eventLoop=0x7ffff6c30050, flags=11) at ae.c:450
#3 0x000000000042a996 in aeMain (eventLoop=0x7ffff6c30050) at ae.c:501
#4 0x0000000000437373 in main (argc=2, argv=0x7fffffffe428) at server.c:4197
master
(gdb) bt
(gdb) bt
#0 pingCommand (c=0x7ffff4961f80) at server.c:2912
#1 0x0000000000432ced in call (c=0x7ffff4961f80, flags=15) at server.c:2433
#2 0x000000000043390f in processCommand (c=0x7ffff4961f80) at server.c:2729
#3 0x00000000004436b6 in processInputBuffer (c=0x7ffff4961f80) at networking.c:1452
#4 0x00000000004437ff in processInputBufferAndReplicate (c=0x7ffff4961f80) at networking.c:1487
#5 0x0000000000443b6f in readQueryFromClient (el=0x7ffff6c30050, fd=9, privdata=0x7ffff4961f80, mask=1) at networking.c:1569
#6 0x000000000042a7b3 in aeProcessEvents (eventLoop=0x7ffff6c30050, flags=11) at ae.c:443
#7 0x000000000042a996 in aeMain (eventLoop=0x7ffff6c30050) at ae.c:501
#8 0x0000000000437373 in main (argc=2, argv=0x7fffffffe428) at server.c:4197
#0 replconfCommand (c=0x7ffff4979100) at replication.c:779
#1 0x0000000000432ced in call (c=0x7ffff4979100, flags=15) at server.c:2433
#2 0x000000000043390f in processCommand (c=0x7ffff4979100) at server.c:2729
#3 0x00000000004436b6 in processInputBuffer (c=0x7ffff4979100) at networking.c:1452
#4 0x00000000004437ff in processInputBufferAndReplicate (c=0x7ffff4979100) at networking.c:1487
#5 0x0000000000443b6f in readQueryFromClient (el=0x7ffff6c30050, fd=15, privdata=0x7ffff4979100, mask=1) at networking.c:1569
#6 0x000000000042a7b3 in aeProcessEvents (eventLoop=0x7ffff6c30050, flags=11) at ae.c:443
#7 0x000000000042a996 in aeMain (eventLoop=0x7ffff6c30050) at ae.c:501
#8 0x0000000000437373 in main (argc=2, argv=0x7fffffffe428) at server.c:4197
server端,strace跟踪,可以看到回复信息
write(8, "+PONG\r\n", 7) = 7
write(8, "+OK\r\n", 5) = 5
write(8, "+OK\r\n", 5) = 5
write(1, "3328:M 22 Feb 2024 03:49:55.597 * Replica 192.168.1.14:6379 asks for synchronization\n", 85) = 85
write(8, "+CONTINUE ab13e684b2c06517032ec446a2679af771452729\r\n", 52) = 52
write(1, "3328:M 22 Feb 2024 03:49:55.599 * Partial resynchronization request from 192.168.1.14:6379 accepted. Sending 66 bytes of backlog starting from offset 1911.\n", 156) = 156
write(8, "*3\r\n$3\r\nset\r\n$4\r\nkey3\r\n$4\r\nval3\r\n*3\r\n$3\r\nset\r\n$4\r\nkey4\r\n$4\r\nval4\r\n", 66) = 66
write(8, "*1\r\n$4\r\nPING\r\n", 14) = 14
同步数据
- slave通过syncWithMaster发送PSYNC
- master通过syncCommand相应PSYNC,返回+FULLERSYNC(全量) or CONTINUE(增量) replId offset
- slave 解析master的reply,注册readSyncBulkPayload回调函数
- master 发送数据给slave
- slave同步数据,readSyncBulkPayload,回复确认ack
协议图示
- 握手过程
- slave状态机
整体协议需要解决数据传输的类型:全量/增量,偏移量和ACK机制
- 如果slave没有收到+FULLERSYNC(全量) or CONTINUE(增量) replId offset,slave需要进入下一次循环try again
- slave依赖状态机来决定操作选择
数据传输
全量同步
master端
master 利用bgsave,生成快照rdb文件/直接socket,发送给slave
-
master 执行 syncCommand 触发startBgsaveForReplication,fork子进程异步生成rdb/socket发送,同步回复FULLERSYNC(全量) or CONTINUE(增量) replId offset
- rdbSaveBackground
- rdbSaveToSlavesSockets
int startBgsaveForReplication(int mincapa) {
int retval;
int socket_target = server.repl_diskless_sync && (mincapa & SLAVE_CAPA_EOF);
listIter li;
listNode *ln;
serverLog(LL_NOTICE,"Starting BGSAVE for SYNC with target: %s",
socket_target ? "replicas sockets" : "disk");
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
/* Only do rdbSave* when rsiptr is not NULL,
* otherwise slave will miss repl-stream-db. */
if (rsiptr) {
if (socket_target)
retval = rdbSaveToSlavesSockets(rsiptr);
else
retval = rdbSaveBackground(server.rdb_filename,rsiptr);
} else {
serverLog(LL_WARNING,"BGSAVE for replication: replication information not available, can't generate the RDB file right now. Try later.");
retval = C_ERR;
}
}
-
子进程复制rbd文件生成/socket read
-
子进程serverCron定时执行backgroundSaveDoneHandler,并执行 updateSlavesWaitingBgsave
-
updateSlavesWaitingBgsave函数,如果bgsave完成,注册新的可写事件,回调函数 sendBulkToSlave,发送给slave
-
注意,这里面是以rdb文件的方式描述的,并没有对 backgroundSaveDoneHandlerSocket 展开
- rdbSaveInfoAuxFields 把内存数据组合成rdb格式,写入socket - fd
/* When a background RDB saving/transfer terminates, call the right handler. */
void backgroundSaveDoneHandler(int exitcode, int bysignal) {
switch(server.rdb_child_type) {
case RDB_CHILD_TYPE_DISK:
backgroundSaveDoneHandlerDisk(exitcode,bysignal);
break;
case RDB_CHILD_TYPE_SOCKET:
backgroundSaveDoneHandlerSocket(exitcode,bysignal);
break;
default:
serverPanic("Unknown RDB child type.");
break;
}
}
/* A background saving child (BGSAVE) terminated its work. Handle this.
* This function covers the case of actual BGSAVEs. */
void backgroundSaveDoneHandlerDisk(int exitcode, int bysignal) {
......
server.rdb_child_pid = -1;
server.rdb_child_type = RDB_CHILD_TYPE_NONE;
server.rdb_save_time_last = time(NULL)-server.rdb_save_time_start;
server.rdb_save_time_start = -1;
/* Possibly there are slaves waiting for a BGSAVE in order to be served
* (the first stage of SYNC is a bulk transfer of dump.rdb) */
updateSlavesWaitingBgsave((!bysignal && exitcode == 0) ? C_OK : C_ERR, RDB_CHILD_TYPE_DISK);
}
/* This function is called at the end of every background saving,
* or when the replication RDB transfer strategy is modified from
* disk to socket or the other way around.
*
* The goal of this function is to handle slaves waiting for a successful
* background saving in order to perform non-blocking synchronization, and
* to schedule a new BGSAVE if there are slaves that attached while a
* BGSAVE was in progress, but it was not a good one for replication (no
* other slave was accumulating differences).
*
* The argument bgsaveerr is C_OK if the background saving succeeded
* otherwise C_ERR is passed to the function.
* The 'type' argument is the type of the child that terminated
* (if it had a disk or socket target). */
void updateSlavesWaitingBgsave(int bgsaveerr, int type) {
......
aeDeleteFileEvent(server.el,slave->fd,AE_WRITABLE);
if (aeCreateFileEvent(server.el, slave->fd, AE_WRITABLE, sendBulkToSlave, slave) == AE_ERR) {
freeClient(slave);
continue;
}
.......
}
void sendBulkToSlave(aeEventLoop *el, int fd, void *privdata, int mask) {
......
/* Before sending the RDB file, we send the preamble as configured by the
* replication process. Currently the preamble is just the bulk count of
* the file in the form "$<length>\r\n". */
if (slave->replpreamble) {
nwritten = write(fd,slave->replpreamble,sdslen(slave->replpreamble));
if (nwritten == -1) {
serverLog(LL_VERBOSE,"Write error sending RDB preamble to replica: %s",
strerror(errno));
freeClient(slave);
return;
}
server.stat_net_output_bytes += nwritten;
sdsrange(slave->replpreamble,nwritten,-1);
if (sdslen(slave->replpreamble) == 0) {
sdsfree(slave->replpreamble);
slave->replpreamble = NULL;
/* fall through sending data. */
} else {
return;
}
}
/* If the preamble was already transferred, send the RDB bulk data. */
lseek(slave->repldbfd,slave->repldboff,SEEK_SET);
buflen = read(slave->repldbfd,buf,PROTO_IOBUF_LEN);
if (buflen <= 0) {
serverLog(LL_WARNING,"Read error sending DB to replica: %s",
(buflen == 0) ? "premature EOF" : strerror(errno));
freeClient(slave);
return;
}
if ((nwritten = write(fd,buf,buflen)) == -1) {
if (errno != EAGAIN) {
serverLog(LL_WARNING,"Write error sending DB to replica: %s",
strerror(errno));
freeClient(slave);
}
return;
}
}
int startBgsaveForReplication(int mincapa){
......
/* If the target is socket, rdbSaveToSlavesSockets() already setup
* the salves for a full resync. Otherwise for disk target do it now.*/
if (!socket_target) {
listRewind(server.slaves,&li);
while((ln = listNext(&li))) {
client *slave = ln->value;
if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_START) {
replicationSetupSlaveForFullResync(slave,
getPsyncInitialOffset());
}
}
}
......
}
全量同步失败如何处理?比如网络断开
- 如果是master断线,master 重新上线后,slave connect 重新走握手流程 - syncCommand 函数处理
- 如果是slave断线,重新上线后,handshake来判断是全量还是增量同步 - slaveTryPartialResynchronization函数处理
Slave端
- 通过slaveTryPartialResynchronization 处理 master 回复:根据回复协议分析,确认数据的复制方式:全量同步/增量同步,并做相应的处理
- syncWithMaster 注册aeCreateFileEvent(server.el,fd, AE_READABLE,readSyncBulkPayload,NULL) 可读事件
- 当接收到master的数据时,回调 readSyncBulkPayload 异步完成
全量同步期间,master继续接收命令,slave阻塞至数据同步完成,两者期间数据不一致
增量同步
Redis 维护一个buf 默认1MB,再加上master/slave各自的offset,完成增量同步
- slave PSYNC时发送offset,master根据自身master-offset和slave-offset 发送缓冲区数据
repl_backlog 是一个char类型的循环缓冲区,在redis.conf 配置 repl-backlog-size
-
循环缓冲区的创建 - createReplicationBacklog
- Redis 是在 syncCommand 函数中,即slave发送PSYNC,调用 createReplicationBacklog 函数来创建循环缓冲区
- 所有slave共享缓冲区
-
循环缓冲区的写操作 - feedReplicationBacklog
-
Redis ,master处理命令触发processInputBufferAndReplicate
- size_t prev_offset = c->reploff;//master维护slave.reploff偏移量
- size_t applied = c->reploff - prev_offset;
- applied>0 调用feedReplicationBacklog
-
feedReplicationBacklog 函数会更新全局变量 server 的 master_repl_offset 值,在当前值的基础上加上要写入的数据长度 len
- server.master_repl_offset += len
-
根据👆的len循环写入数据
-
- 计算本轮循环能写入的数据长度thislen = server.repl_backlog_size - server.repl_backlog_idx
-
- 写入数据 memcpy(server.repl_backlog+server.repl_backlog_idx,p,thislen)
-
- 更新循环缓冲区信息
-
更新缓冲区当前的idx server.repl_backlog_idx += thislen;
- if repl_backlog_idx = repl_backlog_size,repl_backlog_idx 的值会被置为 0 循环的特点
-
更新缓冲区数据长度 server.repl_backlog_histlen += thislen
-
更新剩余待写入数据的长度len -= thislen;
-
更新要写入循环缓冲区的数据指针位置p += thislen;
-
-
如果repl_backlog_histlen的值大于循环缓冲区总长度,那么将该值设置为循环缓冲区总长度
- server.repl_backlog_histlen = server.repl_backlog_size
- 超过长度被丢弃
-
否则 repl_backlog_off = server.master_repl_offset - server.repl_backlog_histlen + 1;
- master_repl_offset
-
-
循环缓冲区的读操作 - addReplyReplicationBacklog
-
slave 发送 PSYNC master调用masterTryPartialResynchronization->addReplyReplicationBacklog 读取buf
-
addReplyReplicationBacklog 执行过程
-
把从节点发送的全局读取位置 offset,减去 repl_backlog_off 的值,从而得到从节点读数据时要跳过的数据长度 skip
-
计算缓冲区中,最早保存的数据的首字节对应在缓冲区中的位置j
-
j = (server.repl_backlog_idx + (server.repl_backlog_size-server.repl_backlog_histlen)) % server.repl_backlog_size;
-
缓冲区还没有写满:repl_backlog_histlen = repl_backlog_idx, j=0
-
缓冲区已经写满过,并且已从头再次写入数据:repl_backlog_histlen = repl_backlog_size,j=repl_backlog_idx
- 再考虑skip 重新计算 j = (j + skip) % server.repl_backlog_size;
-
-
计算读取数据长度len = server.repl_backlog_histlen - skip;
-
循环len读取数据
-
-
#define CONFIG_DEFAULT_REPL_BACKLOG_SIZE (1024*1024) /* 1mb */
#define CONFIG_DEFAULT_REPL_BACKLOG_TIME_LIMIT (60*60) /* 1 hour */
#define CONFIG_REPL_BACKLOG_MIN_SIZE (1024*16) /* 16k */
struct redisServer {
......
long long master_repl_offset; /* My current replication offset */
char *repl_backlog; /* Replication backlog for partial syncs */
long long repl_backlog_size; /* Backlog circular buffer size */
long long repl_backlog_histlen; /* Backlog actual data length */
long long repl_backlog_idx; /* Backlog circular buffer current offset,
that is the next byte will'll write to.*/
long long repl_backlog_off; /* Replication "master offset" of first */
......
}
typedef struct client {
......
long long read_reploff; /* Read replication offset if this is a master. */
long long reploff; /* Applied replication offset if this is a master. */
char replid[CONFIG_RUN_ID_SIZE+1]; /* Master replication ID (if master). */
......
}
/* Add data to the replication backlog.
* This function also increments the global replication offset stored at
* server.master_repl_offset, because there is no case where we want to feed
* the backlog without incrementing the offset. */
void feedReplicationBacklog(void *ptr, size_t len) {
unsigned char *p = ptr;
server.master_repl_offset += len;
/* This is a circular buffer, so write as much data we can at every
* iteration and rewind the "idx" index if we reach the limit. */
while(len) {
size_t thislen = server.repl_backlog_size - server.repl_backlog_idx;
if (thislen > len) thislen = len;
memcpy(server.repl_backlog+server.repl_backlog_idx,p,thislen);
server.repl_backlog_idx += thislen;
if (server.repl_backlog_idx == server.repl_backlog_size)
server.repl_backlog_idx = 0;
len -= thislen;
p += thislen;
server.repl_backlog_histlen += thislen;
}
if (server.repl_backlog_histlen > server.repl_backlog_size)
server.repl_backlog_histlen = server.repl_backlog_size;
/* Set the offset of the first byte we have in the backlog. */
server.repl_backlog_off = server.master_repl_offset -
server.repl_backlog_histlen + 1;
}
/* Feed the slave 'c' with the replication backlog starting from the
* specified 'offset' up to the end of the backlog. */
long long addReplyReplicationBacklog(client *c, long long offset) {
long long j, skip, len;
serverLog(LL_DEBUG, "[PSYNC] Replica request offset: %lld", offset);
if (server.repl_backlog_histlen == 0) {
serverLog(LL_DEBUG, "[PSYNC] Backlog history len is zero");
return 0;
}
serverLog(LL_DEBUG, "[PSYNC] Backlog size: %lld",
server.repl_backlog_size);
serverLog(LL_DEBUG, "[PSYNC] First byte: %lld",
server.repl_backlog_off);
serverLog(LL_DEBUG, "[PSYNC] History len: %lld",
server.repl_backlog_histlen);
serverLog(LL_DEBUG, "[PSYNC] Current index: %lld",
server.repl_backlog_idx);
/* Compute the amount of bytes we need to discard. */
skip = offset - server.repl_backlog_off;
serverLog(LL_DEBUG, "[PSYNC] Skipping: %lld", skip);
/* Point j to the oldest byte, that is actually our
* server.repl_backlog_off byte. */
j = (server.repl_backlog_idx +
(server.repl_backlog_size-server.repl_backlog_histlen)) %
server.repl_backlog_size;
serverLog(LL_DEBUG, "[PSYNC] Index of first byte: %lld", j);
/* Discard the amount of data to seek to the specified 'offset'. */
j = (j + skip) % server.repl_backlog_size;
/* Feed slave with data. Since it is a circular buffer we have to
* split the reply in two parts if we are cross-boundary. */
len = server.repl_backlog_histlen - skip;
serverLog(LL_DEBUG, "[PSYNC] Reply total length: %lld", len);
while(len) {
long long thislen =
((server.repl_backlog_size - j) < len) ?
(server.repl_backlog_size - j) : len;
serverLog(LL_DEBUG, "[PSYNC] addReply() length: %lld", thislen);
addReplySds(c,sdsnewlen(server.repl_backlog + j, thislen));
len -= thislen;
j = 0;
}
return server.repl_backlog_histlen - skip;
}
- 发送数据给slave
见上面的代码addReplySds->_addReplyToBuffer 主线程完成
增量同步机制实现,异步非准实时,master-slave数据会有不一致难过的情况
命令传播同步
通过master-slave之间的长连接,长连接在初次全量同步时建立
每次master 执行写数据命令,同步写入repl_backlog(同增量同步写入和读取buf)发送给slave
支持多个Replication 同步数据
全量,多个slave初次同步数据,master保证一个子进程处理全量数据 增量:master共享repl_backlog,减少内存浪费,同时维护每个slave的repl_off,来决定同步数据量
问题:slave越多,master负担越大,受网络影响越大
链式复制
针对一主多从的弊端,对master压力较大 可以采用master-slave-slave,分担master压力 机制同👆的全量和增量同步
容错处理
定时检测机制
通过 replicationCron 来执行一些定时检查
- 如果长时间处于连接中状态 (REPL_STATE_CONNECTING),超时则取消,调用 cancelReplicationHandshake 释放相关资源
- 如果长时间处于传输中状态 (REPL_STATE_TRANSFER),超时则取消,调用 cancelReplicationHandshake 释放相关资源
- 如果长时间处于连接成功状态(REPL_STATE_CONNECTED),超时则取消,调用 freeClient 释放相关资源
- 上面这些过程,都在slave 执行,并且都会把状态回退到连接初始状态(REPL_STATE_CONNECT),以便重试
- slave如果处于 REPL_STATE_CONNECT,则尝试与 master 连接
- 当与master成功连接后,每隔1秒向master 发送 ack 回复,并带有 offset
- master 定期向 slave 发送 PING 消息,间隔时间通过repl-ping-replica-period
- 当在master下,Slave 处于 BGSAVE 的一系列状态时,通过同步方式发送一个 \n ,相当于PING消息给slave。因为这些阶段可能比较耗时,而输出缓冲也处于暂停输出状态,通过这种方式来告诉slave,其master还在线,阻止其slave 触发超时处理机制
- master 处理slave超时连接,通过最新接受到的 ack 的时间 (slave->repl_ack_time)与超时时间 server.repl_timeout (配置选项repl-timeout来判断
- 如果所有的 slave 都断开,并且超过一定的时间,则 master 释放 backlog 超时配置选项 repl-backlog-ttl
全量/增量同步时断线处理
slave重发送PSYNC命令,发送offset,master判断全量or增量
命令传播同步失败了,连接断开
slave重新建立连接PSYNC,触发增量/全量同步 psync_offset < repl_backlog_off 触发全量,否则增量
repl_backlog 被覆盖了如何处理
如果 psync_offset > (server.repl_backlog_off + server.repl_backlog_histlen)
表示当前 backlog 的数据不够全,则需要进行全量复制
Master故障,slave当选master之后,数据同步如何做?
将在下一篇文章展开
参考
Redis文档more
Redis 5.0.1 source code