Kafka 事务与Exactly Once传递
Exactly Once Delivery and Transactional Messaging in Kafka
本文是阅读笔记,目标
- 掌握kafka事务处理
- 学习如何写tech doc
动机
幂等生产者不能为跨多个 TopicPartition 的写入提供保证。 为此,需要更强的transaction保证,即以原子方式写入多个 TopicPartition 的能力。 我们所说的原子性是指将一组消息作为一个单元跨 TopicPartition 提交的能力。要么所有消息都提交,要么都不提交。
流处理应用程序是“消费-转换-生产”任务的管道,当 流 的重复处理不可接受时,绝对需要事务保证。 因此,向 Kafka(一个流平台)添加事务保证不仅使其对于流处理而且对于各种其他应用程序都更加有用
备注:kafka 事务处理目标是解决多个 TopicPartition 的写入和streaming 架构带来的问题
Transactions and Streams
使用 Kafka Streams 的数据转换通常通过多个流处理器进行,每个流处理器都通过 Kafka 主题连接。 这种设置称为流拓扑,基本上是一个 DAG,其中流处理器是节点,连接的 Kafka 主题是顶点。 这种模式是所有流式架构的典型模式
Kafka 流的事务本质上包含输入消息、本地状态存储的更新以及输出消息。 在事务中包含输入偏移量会促使将 sendOffsets API 添加到 Producer 接口
此外,流拓扑可以变得相当深——10级并不罕见。 如果输出消息仅在事务提交时具体化,则 N 级深的拓扑将需要 N x T 来处理其输入,其中 T 是单个事务的平均时间。 因此,Kafka Streams 需要推测执行,其中输出消息甚至可以在提交之前被下游处理器读取。 否则,事务将不会成为重要的流应用程序的选择。 这激发了稍后描述的“未提交读”消费者模式
Summary of Guarantees
幂等性保证
单一 会话/Topic Partition 保证
详细见之前的文章
事务性保证
正如动机部分中提到的,事务保证使应用程序能够将消费和生成的消息批量放入单个原子单元中
事务中的“batch”消息可以从多个分区消费和写入多个分区,并且是“原子”的,因为写入将作为一个单元失败或成功
有状态应用程序还能够确保应用程序多个会话的连续性 -- 如streaming/故障恢复新的会话
为了实现这一点,我们要求应用程序提供一个在应用程序的所有会话中保持稳定的唯一 ID。 在本文档的其余部分中,我们将此类 id 称为 TransactionalId。 虽然 TransactionalId 和内部 PID 之间可能存在 1-1 映射,但主要区别在于 TransactionalId 是由用户提供的,并且是在下面描述的跨生产者会话之间实现幂等保证的原因
-
Kafka 将保证:
- 跨应用程序会话的幂等性,即使中间故障,恢复后依然可以保持幂等性
- 跨应用程序会话的事务恢复。 如果一个应用程序实例终止,则可以保证下一个实例完成所有未完成的事务(无论是abort还是commit)
消费者视角,kafka保障稍弱一些。 特别是,我们不能保证已提交事务的所有消息都会被一起消耗。原因如下:
- compacted topics 在一个事务中写入的数据可能会被新的值覆盖;
- 事务可能跨越segment log 当删除旧段时(过期淘汰),我们可能会丢失事务中的一些消息
- 消费者可能不会从所有分区中进行消费,只消费一部分时,无法保证所有消息的事务性
- Consumer 在消费时可以通过 seek 机制,随机从一个位置开始消费,这也会导致一个事务内的部分数据无法消费
Design Overview
high level overview of the key concepts
Key Concepts
-
Transactional Messaging
- transaction coordinator 使生产者能够将一组消息作为单个事务发送,该事务要么成功,要么失败
- transaction coordinator 维护了一个事务日志
- 该日志作为内部主题(我们称之为事务主题)存储,以持久保存事务状态以供恢复
-
Offset Commits in Transactions
- 消息的事务性,不仅仅是在生产端,还需要消费端的处理
- 为了实现“Exactly Once”消息传递,我们需要将消费者偏移量的提交作为生产者事务的一部分,以实现原子性
-
Control Messages for Transactions
- Control Message 引入它来标识 append 到log segment 的消息是commit or abort
- Control Message 对用户不可见,仅是broker和clients之间内部使用
- 对于producer事务,我们将引入一组作为Control Message实现的事务标记,以便消费者判断任何给定消息是否commit或abort
-
Producer Identifiers and Idempotency
-
在事务中,我们还需要确保生产者不生成重复的消息
- sequence number
- PID
- TransactionID 支持跨多个topic partition
- 生产者只能有一个正在进行的事务,因此我们可以通过各自的 TransactionalId 来区分属于不同事务的消息。 具有相同 TransactionalId 的生产者将与同一个transaction coordinator通信,该协调器持续跟踪 TransactionalId
-
DataFlow
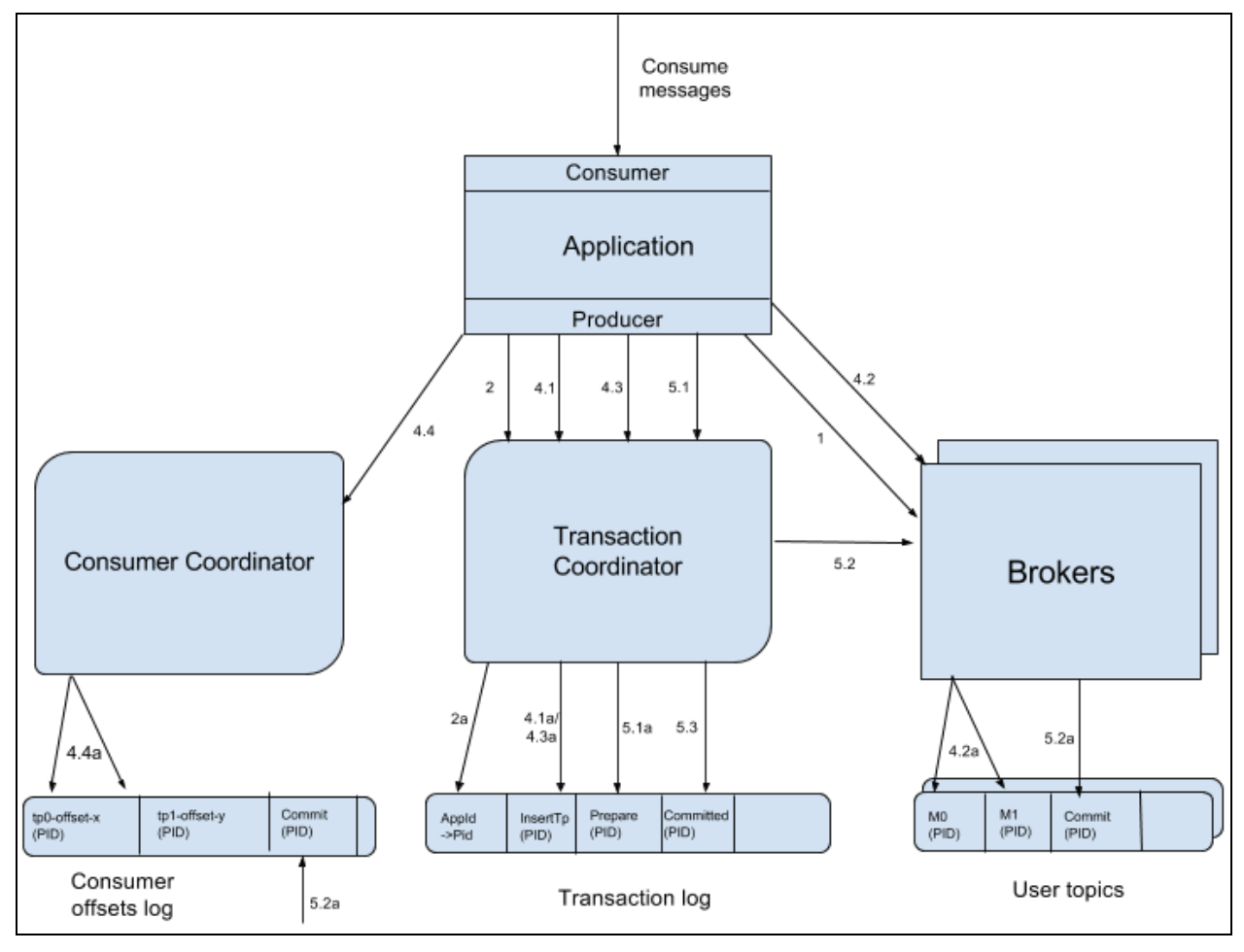
每个箭头代表一个 RPC,或对 Kafka 主题的写入
这些操作按照每个箭头旁边的数字指示的顺序发生
大致的流程,这里不做详细展开:
-
Finding a TransactionCoordinator
- 事务性的处理,第一步首先需要做的就是找到这个事务 txn.id 对应的 TransactionCoordinator
- Transaction Producer 会向 Broker (随机选择一台 broker,一般选择本地连接最少的这台 broker)发送 FindCoordinatorRequest 请求,获取其 TransactionCoordinator
-
Getting a PID Server端分配
-
Starting a Transaction
-
The consume-transform-produce loop
- consumer.poll == records
- start transaction
- producer send records
- producer send offset to transaction
- producer commit transaction
-
Committing or Aborting a Transaction
- 在一个事务操作处理完成之后,Producer 需要调用 commitTransaction() 或者 abortTransaction() 方法来 commit 或者 abort 这个事务操作
Transactional Producer
负责设置TransactionID,start/commit/abort transaction,offset commit
-
Added Configurations
-
enable.idempotence = true
- enforce that acks=all, retries > 1, and max.inflight.requests.per.connection=1
-
transaction.timeout.ms
-
transactional.id
-
Transaction coordinator
Key Concepts 多次提到了Transaction coordinator,它是如何工作的呢?
-
每个broker创建一个协调器,Broker 保障协调器的高可用
-
事务协调器处理来自事务生产者的请求以跟踪其事务状态,并同时通过客户端提供的 TransactionalId 跨多个会话维护其 PID
- Map TransactionalId:PID
- Map PID:Transaction Status
此外,Transaction coordinator还持久化了自己与分区的映射关系,以供故障恢复
Transaction Log
事务日志作为内部事务主题存储在所有代理之间。 事务主题上默认开启日志压缩
-
事务日志作为内部topic __transaction_state,默认开启日志压缩
- 一个事务应该由哪个 TransactionCoordinator 来处理,是根据其 txn.id 的 hash 值与 transaction_state 的 partition 数取模得到,transaction_state Partition 默认是50个,假设取模之后的结果是2,那么这个 txn.id 应该由 __transaction_state Partition 2 的 leader 来处理
- TransactionCoordinator 的恢复是通过 __transaction_state 中读取之前事务的日志信息,来恢复其状态信息,前提是要求事务日志写入做相应的不丢配置
-
附录Transaction State:
- BEGIN
- PREPARE_COMMIT
- PREPARE_ABORT
- COMPLETE_COMMIT
- COMPLETE_ABORT
-
PREPARE_XX 事务消息的写入可以被视为同步点:一旦将其附加(并复制)到日志中,就可以保证事务被提交或中止。 即使协调器发生故障,恢复后该事务也将前滚或回滚。
-
事务超时:使用Transaction State消息的时间戳, 一旦当前时间与State消息中的时间戳之间的差异超过超时时间,事务将被中止
-
事务提交时,协调器将执行以下步骤:
- 向事务添加分区的所有leader发送带有 COMMIT 标记的
- 收到所有响应后,将 COMPLETE_COMMIT 事务消息附加到transaction log
-
中止事务时,协调器将执行以下步骤:
- 将带有 ABORT 标记的 WriteTxnMarkerRequest 发送到事务分区的所有broker。
- 收到所有响应后,将 COMPLETE_ABORT 事务消息附加到transaction log
Discussion on Unavailable Partitions.
分区不可用时,producer commit无法完成,consumer在该分区的消费被阻塞
解决方案:协调器会主动超时事务 aborted 详细见下文
Discussion on Coordinator Failure During Transaction Completion
- 协调器在事务未开始时失败, client重新find 协调器即可
- 协调器在事务处理中失败且client未开启新事务,新的协调器可能会重复某些工作(即事务日志中可能存在重复的 COMMIT 或 ABORT 标记) log),并不会造成什么问题
- 协调器在commit or abort之后失败但client还没有收到影响,client将在找到新的协调器后重试 EndTxnRequest。 只要命令与协调器恢复后事务的完成状态匹配,协调器就会返回成功的响应
Added Broker Configurations
- transactional.id.expiration.ms 默认7天
- max.transaction.timeout.ms 默认15分钟
- transaction.state.log.min.isr 默认2
- transaction.state.log.replication.factor 默认3
- transaction.state.log.num.partitions 默认50
- transaction.state.log.segment.bytes
- transaction.state.log.load.buffer.size
Broker
除了正常处理消息保证不重复之外: 1. 每个broker必须处理从事务协调器发送的请求,以将提交和中止标记写入日志 2. broker还需要处理来自客户端的请求,根据TransactionalId 转到对应的协调器
Transaction Marker
Transaction Marker 也叫做 control messages。它的作用主要是告诉事务操作涉及的 Topic-Partition Set 的 leaders 当前的事务操作已经完成,可以执行 commit 或者 abort。想象一下跨多个RDS数据库的事务提交,类似于2PC保证
这个 marker 数据由该事务的协调器来发送的,producer提交事务,协调器将marker数据发给broker
Discussion on Coordinator Fencing
TransactionCoordinator 在遇到上 long FGC 时,可能会导致 脑裂 问题
这是分布式系统常见的问题
CoordinatorEpoch - 包含在control messages
- 该字段的值对应于给定生产者分配到的transaction log分区的leader epoch。 有了 CoordinatorEpoch 之后,其他 Server 在收到请求时做相应的判断,如果发现 CoordinatorEpoch 值比缓存的最新的值小,那么 Fencing 就生效,拒绝这个请求,也就是 TransactionCoordinator 发送 WriteTxnMarkerRequest 时可能会触发这一机制
Last Stable Offset Tracking
对于一个 Partition 而言,offset 小于 LSO 的数据,全都是已经确定的数据
- 在 READ_COMMITTED 隔离级别中,只有低于 LSO 的偏移量才会暴露给消费者。
- 将条目写入Aborted Transaction Index时需要 LSO 和每个事务的初始偏移量
Aborted Transaction Index
方便consumer 检索过滤 abort 事务
PID-Sequence Management
对于每个 Topic-Partition,Broker 都会在内存中维护其 PID 与 sequence number Epoch(最后成功写入的 msg 的 sequence number)的对应关系
PID Snapshots
Broker 重启时,如果想恢复上面的状态信息,那么它需要读取所有的 log 文件。相比于之下,定期对这个 state 信息做 checkpoint(Snapshot),明显收益是非常大的,此时如果 Broker 重启,只需要读取最近一个 Snapshot 文件,之后的数据再从 log 文件中恢复即可。
PID Expiration
维护PID-Sequence 的Map,有一定成本,需要控制map的大小,因此我们需要一种 PID 过期机制
当ProducerId 的最后一条消息的寿命超过 transactionalId 过期时间或主题的保留时间(以较早发生者为准)时,我们就会使 ProducerId 过期
Discussion on Transaction-based Fencing
与前面的Coordinator Fencing类似
对于相同 PID 和 txn.id 的 Producer,Server 端会记录最新的 Epoch 值,拒绝来自 zombie Producer (Epoch 值小的 Producer)的请求
假设Producer 1失败,Producer2 在启动时,会向 TransactionCoordinator 发送 InitPIDRequest 请求,此时 TransactionCoordinator 已经有了这个 txn.id 对应的 meta,会返回之前分配的 PID,并把 Epoch 自增 1 返回,这样 Producer 2 就被认为是最新的 Producer,而 Producer 1 就会被认为是 zombie Producer,因此,TransactionCoordinator 在处理 Producer 1 的事务请求时,会返回相应的异常信息
Consumer Coordinator
Streaming场景适用
The consume-transform-produce loop 流程在👆已描述
许多 Kafka 流应用程序需要同时从输入主题进行消费并生成输出主题。 当为输入主题提交消费者偏移量时,它们也需要与生成的事务一起完成
Discussion on Reusing Offset Topics within Transactions
假设一个应用程序任务从主题 Tc 消费、处理输入消息并生成主题 Tp
应用程序任务可以使用单独的主题(例如 Tio )来存储输入偏移量
应用程序以这种方式持久保存消耗的偏移量,将consumer.pull与producer.send纳入到一个事务中
Consumer
Added Configurations and Consume Protocol
isolation.level :
- read_uncommitted 默认
- read_committed
消费者在从broker fetch消息时需要识别transaction marker,并根据其配置参数来确定是只返回已提交的消息还是所有消息(无论是否已提交)。 无论哪种情况,消息总是按偏移顺序传递。
隔离级别在 FetchRequest 中传递给代理。 对于 READ_UNCOMMITTED,消费者使用与以前版本的 Kafka 相同的获取逻辑。 对于 READ_COMMITTED,消费者必须做一些额外的工作来过滤中止的事务:
-
Abort Transaction Index的作用
-
Consumer 在拉取数据时,Broker 会把这批数据涉及到的所有 abort transaction 信息都返回给 Consumer,Server 端会根据拉取的 offset 范围与 abort transaction 的 offset 做对比,返回涉及到的 abort transaction 集合
-
Consumer 在拿到这些数据之后,会进行相应的过滤,大概的判断逻辑如下(Server 端返回的 abort transaction 列表就保存在 abortedTransactions 集合中,abortedProducerIds 最开始时是为空的): - 如果这个数据是 control msg(也即是 marker 数据),是 ABORT 的话,那么与这个事务相关的 PID 信息从 abortedProducerIds 集合删掉,是 COMMIT 的话,就忽略(每个这个 PID 对应的 marker 数据收到之后,就从 abortedProducerIds 中清除这个 PID 信息); - 如果这个数据是正常的数据,把它的 PID 和 offset 信息与 abortedTransactions 队列(有序队列,头部 transaction 的 first offset 最小)第一个 transaction 做比较,如果 PID 相同,并且 offset 大于等于这个 transaction 的 first offset,就将这个 PID 信息添加到 abortedProducerIds 集合中,同时从 abortedTransactions 队列中删除这个 transaction,最后再丢掉这个 batch(它是 abort transaction 的数据); - 检查这个 batch 的 PID 是否在 abortedProducerIds 集合中,在的话,就丢弃,不在的话就返回上层应用。
Discussion on Pro-active Transaction Timeout
主动超时的动机时,在Producer失败时,我们不希望依赖生产者最终恢复并完成事务
-
-
如果生产者在事务中失败并且协调器没有abort 这个事务,该事务将成为“悬空”事务,直到生产者使用相同的 TransactionalId 恢复时才会完成,并且任何在 READ_COMMITTED 中包含在该事务中的分区上进行fetch的消费者都将被blocked
-
协调器主动超时 还可以阻止 僵尸producer的写入
- 一旦超时并中止事务,协调器将更改与 PID 关联的epoch,并将 ABORT 标记写入事务包含的所有分区
Discussion on Transaction Ordering
在此设计中,我们假设消费者按偏移顺序传递消息,以保留 Kafka 用户当前期望的行为
还有一种方案时按照事务提交的顺序传递消息:
-
优点是 减少了延时
-
缺点
- 手动管理偏移量的应用程序需要更多的存储成本,应用程序至少需要保留第一条丢失的消息以及它已经处理过的所有其他消息
- 自动提交偏移量,提交时,我们必须跟踪最后处理的提交偏移量的位置