Elasticsearch 源码 - Replication Model
背景
每个 Elasticsearch 索引都被划分为多个分片,每个分片可以有多个副本。这些副本被称为复制组,当文档被添加或删除时,必须保持副本之间的同步。如果我们未能做到这一点,从一个副本读取的数据将与从另一个副本读取的数据有很大不同。保持分片副本同步并从中提供读取服务的过程就是数据复制模型
Elasticsearch 的数据复制模型基于主备模型(在微软研究院的 PacificA 论文中有详细描述)。该模型的基础是复制组中有一个副本作为主分片,其他副本称为副本分片。主分片作为所有索引操作的主要入口,负责验证操作并确保其正确性。一旦索引操作被主分片接受,主分片还负责将该操作复制到其他副本
源码: 8.13
Basic write model
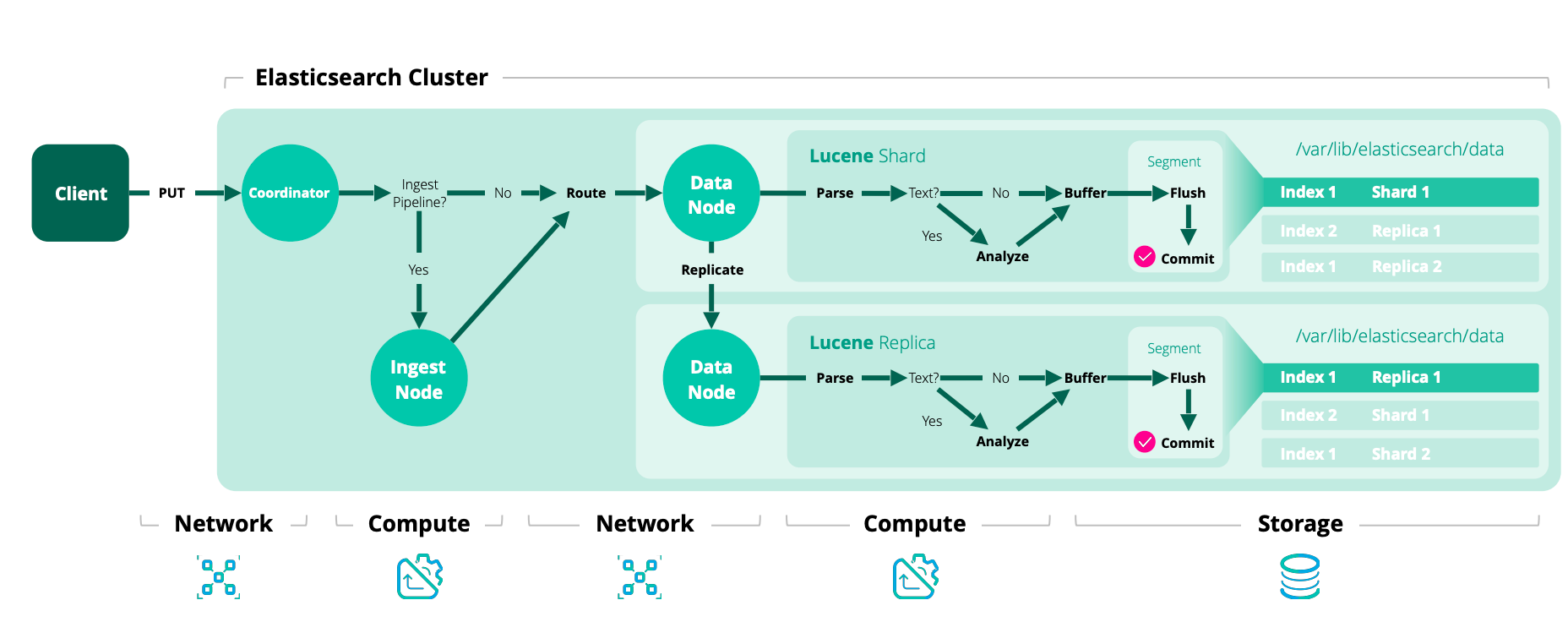
在 Elasticsearch 中,每个索引操作首先通过路由(通常基于文档 ID)解析为一个复制组。一旦确定了复制组,该操作会内部转发到该组的当前主分片。这一索引阶段被称为协调阶段。
主分片阶段,在主分片上执行。主分片负责验证操作并将其转发到其他副本。由于副本可能离线,主分片不需要将操作复制到所有副本。相反,Elasticsearch 维护一个应接收该操作的分片副本列表。这个列表被称为同步副本集(in-sync copies),由主节点维护。顾名思义,这些是确保已处理所有已向用户确认的索引和删除操作的“良好”分片副本。主分片负责维护这一不变量,因此必须将所有操作复制到该集合中的每个副本。
主分片遵循以下基本流程:
- 验证传入操作,如果结构无效则拒绝(例如:期望是一个数字字段,但实际是一个对象字段)。
- 在本地执行操作,即索引或删除相关文档。这也将验证字段内容,并在需要时拒绝(例如:Lucene 中的索引关键词值过长)。
- 将操作转发到当前同步副本集中的每个副本。如果有多个副本,则并行完成此操作。
- 一旦所有同步副本成功执行了操作并响应主分片,主分片就会向客户端确认请求成功完成。
每个同步副本,在本地执行索引操作以保持副本。这一索引阶段称为副本阶段。
这些索引阶段(协调阶段、主阶段和副本阶段)是按顺序进行的。为了实现内部重试,每个阶段的生命周期都涵盖了随后的每个阶段的生命周期。例如,协调阶段在各个主分片上的每个主阶段完成之前不会结束。每个主阶段在同步的副本本地完成文档索引并响应副本请求之前也不会结束。
Failure handling
索引过程中可能出现多种问题,如磁盘损坏、节点断开连接或配置错误,主分片需要对这些问题进行响应
-
如果主分片发生故障,托管主分片的节点会向主节点发送消息,等待主节点将一个副本提升为新的主分片
-
主分片在执行成功后必须处理副本分片上的潜在故障
- 一个处于同步副本集中的副本错过了即将被确认的操作。为了避免违反不变性,主分片会向主节点发送消息,请求将有问题的分片从同步副本集中移除。只有在主节点确认删除该分片后,主分片才确认该操作。请注意,主节点还会指示另一个节点开始构建一个新的分片副本,以将系统恢复到健康状态
-
在将操作转发到副本时,主分片将使用副本来验证其仍然是活动主分片。如果主分片由于网络分区(或长时间的垃圾回收)而被隔离,它可能会继续处理传入的索引操作,然后才意识到它已被降级。来自陈旧主分片的操作将被副本拒绝。当主分片收到副本拒绝其请求的响应,因为它不再是主分片时,它将与主节点联系,并了解到自己已被替换。然后,操作将路由到新的主分片
如果没有副本会发生什么?
在这种情况下,主分片将在没有任何外部验证的情况下处理操作,这可能看起来有问题
- 主分片无法自行使其他分片失败,但会请求主节点代表其执行此操作
- 这意味着主节点知道主分片是唯一的有效副本
我们可以确保主节点不会提升任何其他(out-of-date)分片副本为新的主分片,并且在主分片中索引的任何操作都不会丢失。当然,由于此时我们只使用了数据的单个副本,物理硬件问题可能导致数据丢失
Basic read model
在Elasticsearch中,读取操作可以是非常轻量级的按ID查找,也可以是具有复杂聚合的重型搜索请求,这需要相当大的CPU计算力。主备模型的一个优点是它保持所有分片副本的一致性(除了正在进行的操作)。因此,单个同步副本就足以处理读取请求。
当一个节点接收到读取请求时,该节点负责将其转发到持有相关分片的节点,整理响应,并向客户端响应。我们将该节点称为该请求的协调节点。基本流程如下:
-
将读取请求解析为相关分片。请注意,由于大多数搜索将被发送到一个或多个索引,它们通常需要从多个分片中读取数据,每个分片代表数据的不同子集
-
从分片复制组中选择每个相关分片的活动副本,这可以是主分片或副本。默认情况下, Elasticsearch使用自适应副本选择来选择分片副本
- 协调节点(coordinating node)与合适节点(eligible node)之间先前请求的响应时间
- eligible节点运行先前搜索所花费的时间
- eligible节点搜索线程池的队列大小
- 自适应副本选择旨在降低搜索延迟。但是,您可以通过使用集群设置 API 将 cluster.routing.use_adaptive_replica_selection 设置为 false 来禁用自适应副本选择。如果禁用,Elasticsearch 将使用循环轮询方法路由搜索请求,这可能导致搜索速度较慢
-
将分片级别的读取请求发送到所选副本。
-
合并结果并响应。请注意,在按ID查找时,只有一个分片是相关的,可以跳过此步骤
提示
这些基本流程决定了 Elasticsearch 作为读取和写入系统的行为方式。此外,由于读取和写入请求可以并发执行,这两种基本流程相互影响。这具有一些固有的含义:
-
高效的读取
- 在正常操作下,每个读取操作都针对每个相关的复制组执行一次。只有在故障情况下,才会有多个副本执行相同的搜索。
-
读取未确认
- 由于主节点首先在本地进行索引,然后复制请求,因此在已经确认之前,并发读取可能已经看到变更。
-
默认两个副本
- 这种模型在只维护两个副本的情况下可以实现容错性。这与基于法定人数的系统形成对比,后者对于容错性的最小副本数量为 3
故障
在发生故障时,可能会出现以下情况:
-
单个分片可能会减慢索引速度
- 因为主分片在每个操作期间都等待所有同步副本组中的副本,所以单个缓慢的分片可能会减慢整个复制组的速度。这就是我们为了上述读取效率所付出的代价。当然,单个缓慢的分片也会减慢被路由到它的不幸搜索。
-
脏读
- 一个孤立的主分片可能会暴露出不会被确认的写入。这是因为孤立的主分片只有在向其副本发送请求或与主节点联系时才会意识到自己已被孤立。在那时,操作已经被索引到主分片中,并且可以被并发读取。Elasticsearch 通过每秒(默认值)向主节点发送 ping 请求并拒绝索引操作(如果没有已知的主节点)来减轻此风险
多副本一致性保证
Translog
- Translog 是每个索引分片的组件,以持久的方式记录所有索引操作
- 主分片通过为索引的操作分配连续的序列号来确定操作发生的顺序
- 序列号代表事务日志中被操作占据的槽位
- 当在主分片上进行的写操作被复制到副本时,复制请求包含在主分片上分配给该操作的序列号。然后,副本将操作分配到其事务日志中的相同槽位
- 由于复制的并发性,副本可能会乱序填充这些槽位
- 如果主分片崩溃或某些复制请求未到达副本,副本可能会处于事务日志中有空洞的状态(某些槽位未填充,而后续槽位已填充)
Example of a transaction log on the primary and a replica:
---------------------
| 1 | 2 | 3 | 4 | 5 |
primary |-------------------|
| x | x | x | x | |
---------------------
---------------------
| 1 | 2 | 3 | 4 | 5 |
replica |-------------------| (request for slot 2 is still in-flight)
| x | | x | x | |
---------------------
CheckPoint
translog对应一个ckp文件
//主要作用是管理 Elasticsearch 中 translog 的检查点,通过记录操作的偏移量、操作数、生成号、序列号和全局检查点等信息,确保在故障恢复时能够准确地找到未提交的操作,从而保证数据的一致性和持久性
final class Checkpoint {
final long offset;
final int numOps;
final long generation;
final long minSeqNo;
final long maxSeqNo;
final long globalCheckpoint;
final long minTranslogGeneration;
final long trimmedAboveSeqNo;
......
/**
* Create a new translog checkpoint.
*
* @param offset the current offset in the translog
* @param numOps the current number of operations in the translog
* @param generation the current translog generation
* @param minSeqNo the current minimum sequence number of all operations in the translog
* @param maxSeqNo the current maximum sequence number of all operations in the translog
* @param globalCheckpoint the last-known global checkpoint
* @param minTranslogGeneration the minimum generation referenced by the translog at this moment.
* @param trimmedAboveSeqNo all operations with seq# above trimmedAboveSeqNo should be ignored and not read from the
* corresponding translog file. {@link SequenceNumbers#UNASSIGNED_SEQ_NO} is used to disable trimming.
*/
......
}
Local CheckPoint
副本分片会向主节点共享其已填充的最高槽位信息,并确保其下的所有槽位也已填充,这称为本地检查点
注意,这是所有较低序列号都已处理完的最高序列号。不是分片处理过的最高序列号,因为并发索引意味着某些更早的redo操作可能仍在进行中
Global CheckPoint
这是本地分片可以保证所有之前(包括它)序列号在所有活动分片副本(即主节点和副本)上都已处理完的最高序列号
主节点将各个分片副本(包括自身)的本地检查点值的最小值设定为全局检查点,并将此信息广播给各个副本,大家共享
👆这两个数字将保存在内存中,同时也会持久化在Lucene元数据中
Sequence No. and Term
在主节点上记录操作顺序可以通过一个简单的增量计数来解决,即对每个操作递增一个本地计数器。然而,在发生错误-例如主分片被网络分区隔离 条件下,本地计数器难以保证全局唯一性和单调性。为了解决这个问题,需要将当前主节点的身份信息嵌入到每个操作中。例如,来自旧主节点的延迟操作可以被检测并拒绝
每个操作都会被分配两个数字:
- term(术语):这个数字在每次主节点分配时递增,由集群主节点确定。这与Raft中的term或Zab中的epoch相似
- seq#(序列号):这个数字由主节点(主分片)在处理每个操作时递增
为了实现排序,当比较两个操作 o1 和 o2 时,我们说 o1 < o2 当且仅当 s1.seq# < s2.seq# 或 (s1.seq# == s2.seq# 并且 s1.term < s2.term)。相等和大于的定义方式类似
public abstract static sealed class Operation implements Writeable permits Delete, Index, NoOp {
public enum Type {
@Deprecated
CREATE((byte) 1),
INDEX((byte) 2),
DELETE((byte) 3),
NO_OP((byte) 4);
private final byte id;
Type(byte id) {
this.id = id;
}
public byte id() {
return this.id;
}
public static Type fromId(byte id) {
return switch (id) {
case 1 -> CREATE;
case 2 -> INDEX;
case 3 -> DELETE;
case 4 -> NO_OP;
default -> throw new IllegalArgumentException("no type mapped for [" + id + "]");
};
}
}
protected final long seqNo;
protected final long primaryTerm;
......
Handle Replication Request
//TransportReplicationAction.java
/**
* The {@code ReplicasProxy} is an implementation of the {@code Replicas}
* interface that performs the actual {@code ReplicaRequest} on the replica
* shards. It also encapsulates the logic required for failing the replica
* if deemed necessary as well as marking it as stale when needed.
*/
protected class ReplicasProxy implements ReplicationOperation.Replicas<ReplicaRequest> {
@Override
public void performOn(
final ShardRouting replica,
final ReplicaRequest request,
final long primaryTerm,
final long globalCheckpoint,
final long maxSeqNoOfUpdatesOrDeletes,
final ActionListener<ReplicationOperation.ReplicaResponse> listener
) {
String nodeId = replica.currentNodeId();
final DiscoveryNode node = clusterService.state().nodes().get(nodeId);
if (node == null) {
listener.onFailure(new NoNodeAvailableException("unknown node [" + nodeId + "]"));
return;
}
final ConcreteReplicaRequest<ReplicaRequest> replicaRequest = new ConcreteReplicaRequest<>(
request,
replica.allocationId().getId(),
primaryTerm,
globalCheckpoint,
maxSeqNoOfUpdatesOrDeletes
);
final ActionListenerResponseHandler<ReplicaResponse> handler = new ActionListenerResponseHandler<>(
listener,
ReplicaResponse::new,
TransportResponseHandler.TRANSPORT_WORKER
);
transportService.sendRequest(node, transportReplicaAction, replicaRequest, transportOptions, handler);
}
protected void handleReplicaRequest(
final ConcreteReplicaRequest<ReplicaRequest> replicaRequest,
final TransportChannel channel,
final Task task
) {
Releasable releasable = checkReplicaLimits(replicaRequest.getRequest());
ActionListener<ReplicaResponse> listener = ActionListener.runBefore(new ChannelActionListener<>(channel), releasable::close);
try {
new AsyncReplicaAction(replicaRequest, listener, (ReplicationTask) task).run();
} catch (RuntimeException e) {
listener.onFailure(e);
}
}
private final class AsyncReplicaAction extends AbstractRunnable implements ActionListener<Releasable> {
......
@Override
protected void doRun() throws Exception {
setPhase(task, "replica");
final String actualAllocationId = this.replica.routingEntry().allocationId().getId();
if (actualAllocationId.equals(replicaRequest.getTargetAllocationID()) == false) {
throw new ShardNotFoundException(
this.replica.shardId(),
"expected allocation id [{}] but found [{}]",
replicaRequest.getTargetAllocationID(),
actualAllocationId
);
}
acquireReplicaOperationPermit(
replica,
replicaRequest.getRequest(),
this,
replicaRequest.getPrimaryTerm(),
replicaRequest.getGlobalCheckpoint(),
replicaRequest.getMaxSeqNoOfUpdatesOrDeletes()
);
}
public void onResponse(Releasable releasable) {
assert replica.getActiveOperationsCount() != 0 : "must perform shard operation under a permit";
try {
shardOperationOnReplica(
replicaRequest.getRequest(),
replica,
ActionListener.wrap((replicaResult) -> replicaResult.runPostReplicaActions(ActionListener.wrap(r -> {
final ReplicaResponse response = new ReplicaResponse(
replica.getLocalCheckpoint(),
replica.getLastSyncedGlobalCheckpoint()
);
releasable.close(); // release shard operation lock before responding to caller
if (logger.isTraceEnabled()) {
logger.trace(
"action [{}] completed on shard [{}] for request [{}]",
transportReplicaAction,
replicaRequest.getRequest().shardId(),
replicaRequest.getRequest()
);
}
setPhase(task, "finished");
onCompletionListener.onResponse(response);
}, e -> {
Releasables.closeWhileHandlingException(releasable); // release shard operation lock before responding to caller
responseWithFailure(e);
})), e -> {
Releasables.closeWhileHandlingException(releasable); // release shard operation lock before responding to caller
AsyncReplicaAction.this.onFailure(e);
})
);
// TODO: Evaluate if we still need to catch this exception
} catch (Exception e) {
Releasables.closeWhileHandlingException(releasable); // release shard operation lock before responding to caller
AsyncReplicaAction.this.onFailure(e);
}
}
//最终调用IndexShard.java
private void innerAcquireReplicaOperationPermit(
final long opPrimaryTerm,
final long globalCheckpoint,
final long maxSeqNoOfUpdatesOrDeletes,
final ActionListener<Releasable> onPermitAcquired,
final boolean allowCombineOperationWithPrimaryTermUpdate,
final Consumer<ActionListener<Releasable>> operationExecutor
) {
verifyNotClosed();
// This listener is used for the execution of the operation. If the operation requires all the permits for its
// execution and the primary term must be updated first, we can combine the operation execution with the
// primary term update. Since indexShardOperationPermits doesn't guarantee that async submissions are executed
// in the order submitted, combining both operations ensure that the term is updated before the operation is
// executed. It also has the side effect of acquiring all the permits one time instead of two.
final ActionListener<Releasable> operationListener = onPermitAcquired.delegateFailure((delegatedListener, releasable) -> {
if (opPrimaryTerm < getOperationPrimaryTerm()) {
releasable.close();
final String message = String.format(
Locale.ROOT,
"%s operation primary term [%d] is too old (current [%d])",
shardId,
opPrimaryTerm,
getOperationPrimaryTerm()
);
delegatedListener.onFailure(new IllegalStateException(message));
} else {
assert assertReplicationTarget();
try {
updateGlobalCheckpointOnReplica(globalCheckpoint, "operation");
advanceMaxSeqNoOfUpdatesOrDeletes(maxSeqNoOfUpdatesOrDeletes);
} catch (Exception e) {
releasable.close();
delegatedListener.onFailure(e);
return;
}
delegatedListener.onResponse(releasable);
}
});
if (requirePrimaryTermUpdate(opPrimaryTerm, allowCombineOperationWithPrimaryTermUpdate)) {
synchronized (mutex) {
if (requirePrimaryTermUpdate(opPrimaryTerm, allowCombineOperationWithPrimaryTermUpdate)) {
final IndexShardState shardState = state();
// only roll translog and update primary term if shard has made it past recovery
// Having a new primary term here means that the old primary failed and that there is a new primary, which again
// means that the master will fail this shard as all initializing shards are failed when a primary is selected
// We abort early here to prevent an ongoing recovery from the failed primary to mess with the global / local checkpoint
if (shardState != IndexShardState.POST_RECOVERY && shardState != IndexShardState.STARTED) {
throw new IndexShardNotStartedException(shardId, shardState);
}
bumpPrimaryTerm(opPrimaryTerm, () -> {
updateGlobalCheckpointOnReplica(globalCheckpoint, "primary term transition");
final long currentGlobalCheckpoint = getLastKnownGlobalCheckpoint();
final long maxSeqNo = seqNoStats().getMaxSeqNo();
logger.info(
"detected new primary with primary term [{}], global checkpoint [{}], max_seq_no [{}]",
opPrimaryTerm,
currentGlobalCheckpoint,
maxSeqNo
);
if (currentGlobalCheckpoint < maxSeqNo) {
resetEngineToGlobalCheckpoint();
} else {
getEngine().rollTranslogGeneration();
}
}, allowCombineOperationWithPrimaryTermUpdate ? operationListener : null);
if (allowCombineOperationWithPrimaryTermUpdate) {
logger.debug("operation execution has been combined with primary term update");
return;
}
}
}
}
assert opPrimaryTerm <= pendingPrimaryTerm
: "operation primary term [" + opPrimaryTerm + "] should be at most [" + pendingPrimaryTerm + "]";
operationExecutor.accept(operationListener);
}
public static WriteReplicaResult<BulkShardOperationsRequest> shardOperationOnReplica(
final BulkShardOperationsRequest request,
final IndexShard replica,
final Logger logger
) throws IOException {
assert replica.getMaxSeqNoOfUpdatesOrDeletes() >= request.getMaxSeqNoOfUpdatesOrDeletes()
: "mus on replica [" + replica + "] < mus of request [" + request.getMaxSeqNoOfUpdatesOrDeletes() + "]";
Translog.Location location = null;
for (final Translog.Operation operation : request.getOperations()) {
final Engine.Result result = replica.applyTranslogOperation(operation, Engine.Operation.Origin.REPLICA);
if (result.getResultType() != Engine.Result.Type.SUCCESS) {
assert false : "doc-level failure must not happen on replicas; op[" + operation + "] error[" + result.getFailure() + "]";
throw ExceptionsHelper.convertToElastic(result.getFailure());
}
assert result.getSeqNo() == operation.seqNo();
location = locationToSync(location, result.getTranslogLocation());
}
assert request.getOperations().size() == 0 || location != null;
return new WriteReplicaResult<>(request, location, null, replica, logger);
}
......
代码很多,逻辑相对清晰:
-
处理低任期请求:
- 如果请求的任期(m.rterm)小于当前节点的任期(currentTerm[n]),则拒绝该请求,并返回失败响应(FailedResponse)- delegatedListener.onFailure(new IllegalStateException(message))
-
处理高任期请求:
-
如果请求的任期大于或等于当前节点的任期:
- 首先,检查消息是否是复制请求assertReplicationTarget()
- 计算新的全局检查点 newGlobalCheckpoint,取当前全局检查点和消息中的全局检查点的最大值 - updateGlobalCheckpointOnReplica / advanceMaxSeqNoOfUpdatesOrDeletes
- 更新事务日志 newTlog,包含新的条目并根据新的任期和全局检查点标记待确认条目 - shardOperationOnReplica
- 重新计算本地检查点 localCP
-
👆这样的操作就可以保证一致性了吗?
lucene index 同步问题
checkpoint可以帮组检查translog在各分片的水位但lucene index没有这个机制
各个分片lucene segment flush不同步,会出现数据不一致性
index处理先于translog
InternalEngine.java
......
if (index.origin() == Operation.Origin.PRIMARY) {
index = new Index(
index.uid(),
index.parsedDoc(),
generateSeqNoForOperationOnPrimary(index),
index.primaryTerm(),
index.version(),
index.versionType(),
index.origin(),
index.startTime(),
index.getAutoGeneratedIdTimestamp(),
index.isRetry(),
index.getIfSeqNo(),
index.getIfPrimaryTerm()
);
final boolean toAppend = plan.indexIntoLucene && plan.useLuceneUpdateDocument == false;
if (toAppend == false) {
advanceMaxSeqNoOfUpdatesOnPrimary(index.seqNo());
}
} else {
markSeqNoAsSeen(index.seqNo());
}
assert index.seqNo() >= 0 : "ops should have an assigned seq no.; origin: " + index.origin();
if (plan.indexIntoLucene || plan.addStaleOpToLucene) {
indexResult = indexIntoLucene(index, plan);
} else {
indexResult = new IndexResult(
plan.versionForIndexing,
index.primaryTerm(),
index.seqNo(),
plan.currentNotFoundOrDeleted,
index.id()
);
}
}
if (index.origin().isFromTranslog() == false) {
final Translog.Location location;
if (indexResult.getResultType() == Result.Type.SUCCESS) {
location = translog.add(new Translog.Index(index, indexResult));
......
参考
- Elasticsearch源码 8.13
- 官方文档
- Replication TLA